TACAS 2015
Detailed Measurement Results for TACAS 2015
On this page we detail our most recent measurement results comparing some state-of-the-art model checkers to our algorithm based on models of the Model Checking Contest. A total of 7850 measurements were done with 4 tools. We process the collected data continuously, so this page is updated from time to time to present more detailed plots and descriptions.
Tools
The tools and algorithms included in the measurements are the following:
- NuSMV2: traditional BDD-based fixed point computations,
- nuXmv (NuSMV3): the newest generation of SAT-based model checking algorithms (so-called IC3), various abstraction and reduction techniques,
- ITS-LTL: the newest variant of saturation based model checking algorithms based on different automaton representations and optimizations,
- Hybrid MC: the prototype of our algorithm presented in the submitted paper currently implemented in C#.
Models
The models used in the measurements are P/T models of the Model Checking Contest, please refer to their official website for details.
ITS was run on CAMI models converted from PNML models with CAMI2PNML.
NuSMV and nuXmv processed SMV models generated with our tool, evaluating variable bounds where possible.
Variable ordering files were generated by the Python scripts that come with ITS-Tools (heuristics 11, flat). All algorithms that accept variable oderings were run with the same ordering.
Models were split into scalable cathegories, yielding 29 types of models. Many of these contain more than one actual model instance, each of them instantiated with a different scaling parameter. The total number of measured model instances is 157.
Expressions
50 random LTL expressions were generated for each type of models, containing atomic propositions referring to the common elements in the different instances of the model type. The expressions were generated by SPOT with a length of at most 15, filtering out pure boolean formulae. These expressions were converted into the native syntax of each tool (in the case of Hybrid-MC, SPOT was used to generate generalized Büchi automata).
Reproducibility
The measurement package containing every artifact necessary for reproducing our results can be downloaded here. Each tool can be run separately with the correspongind shell scripts (cygwin is required on Windows), given that the directory structure is not changed.
WARNING: The measurement package contains executables in order to provide a way to exactly reproduce our results, use them only for this purpose. If you need any of the tools for other use, the newest versions are available from their official websites with the proper licensing (all of them are free for personal and academic use).
All measurements were done on identical server machines with Intel® Xeon™ processors (2.2 GHz) and 8 GB RAM. ITS and Hybrid MC were run on Microsoft Windows 7, while runtimes of NuSMV and NuXMV were measured on CentOS 6.5. Timeout was set to 600 seconds.
Results
Processed runtime results of our measurements are available in CSV format.
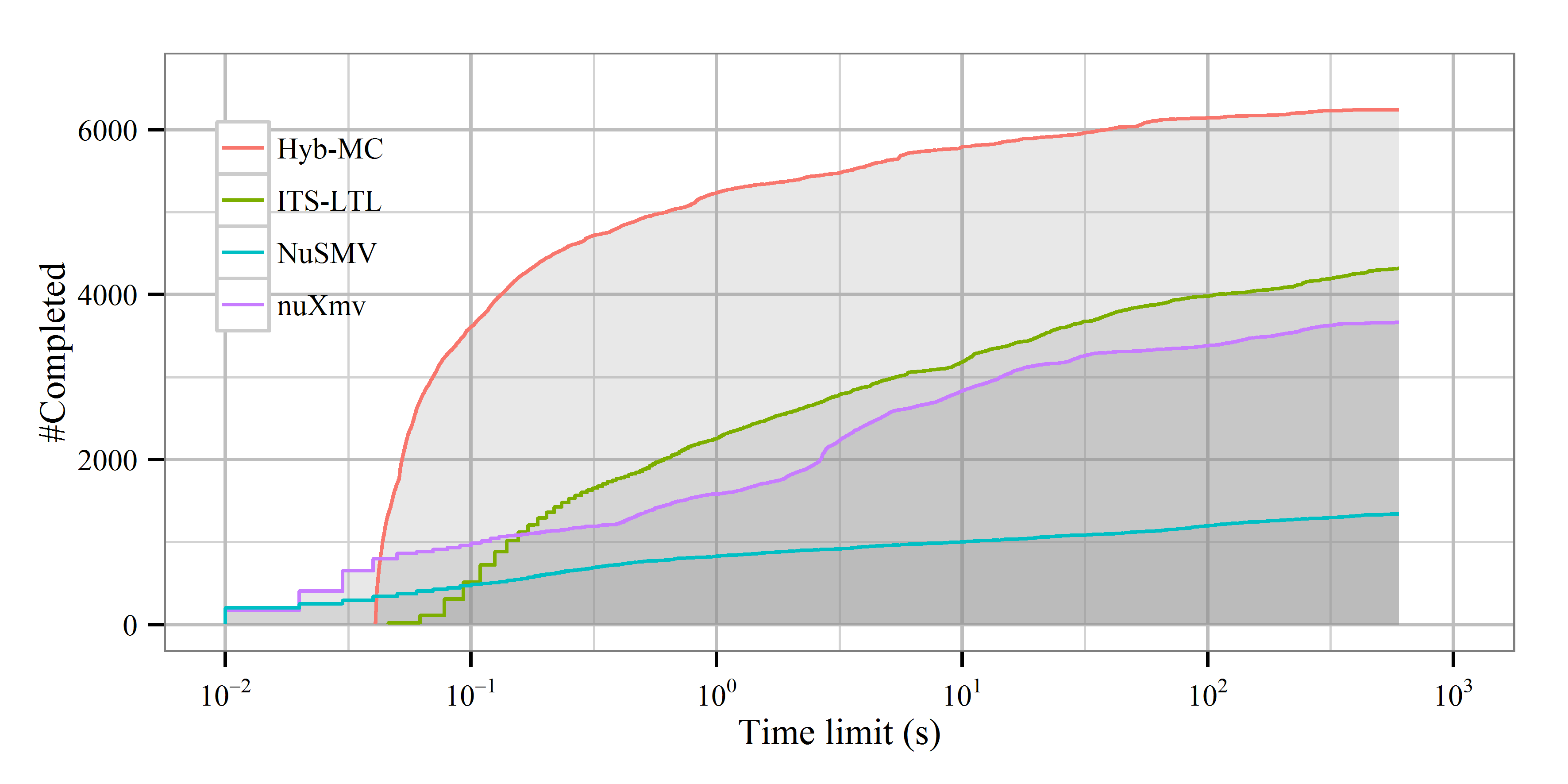
The following three scatterplots visualize the relative performance of Hybrid MC compared to the other three tools and saturation-based state space generation. With the runtime of Hybrid MC on the X axis and the runtime of the other tool on the Y axis, each point corresponds to an individual measurement. When a point is in the upper-left half of the plot, Hybrid MC was faster. Be aware that the axes are logarithmic.

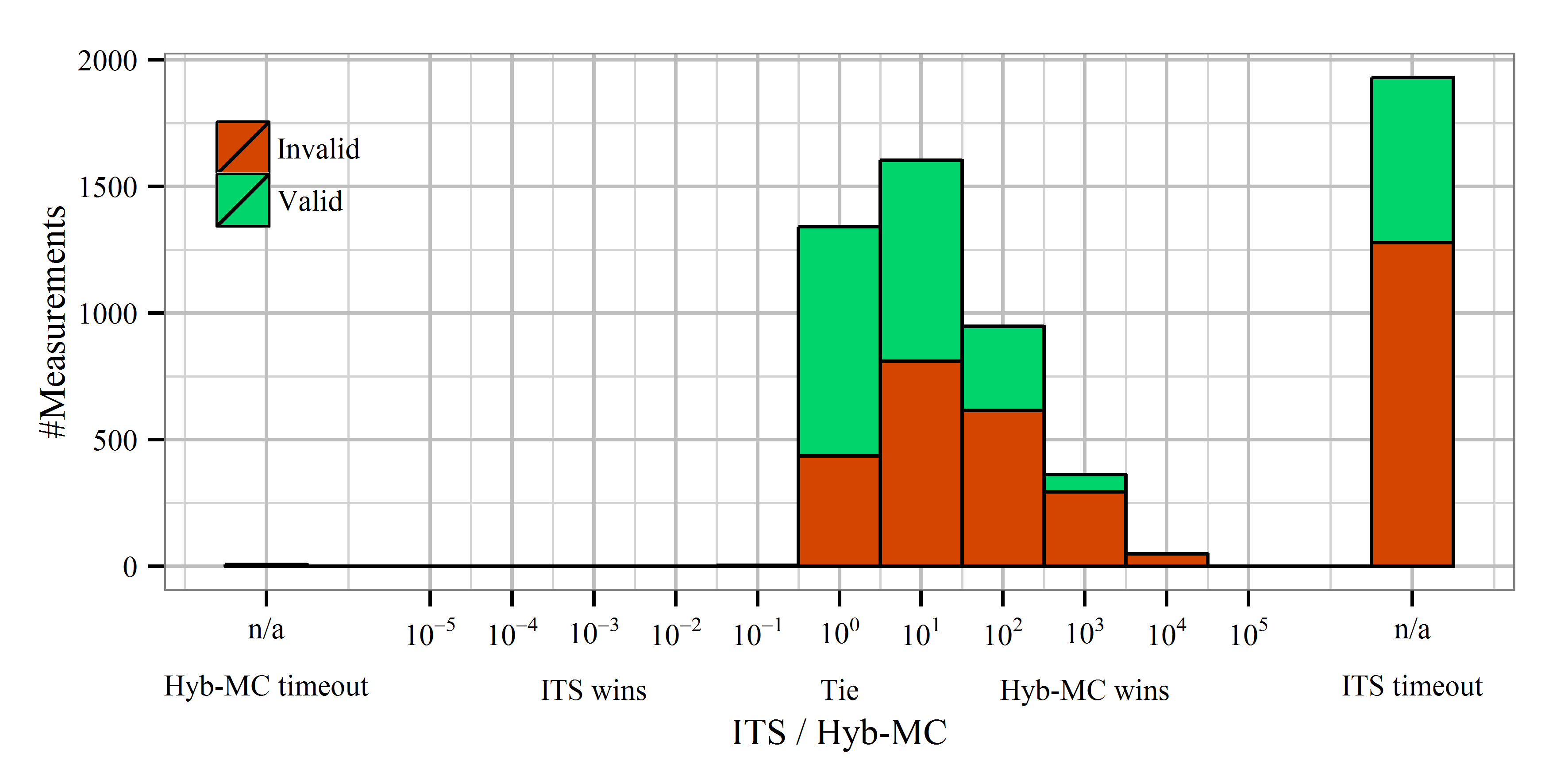
Points near the diagonal line mark cases in which runtimes were similar – the further the point is from this line, the higher the difference is. The following histogram quantifies this difference into different orders of magnitudes. The plot shows the distribution of the quotient tcompetitor/tHyb-MC on a logarithic scale. In addition, colors show if the property was valid or not.
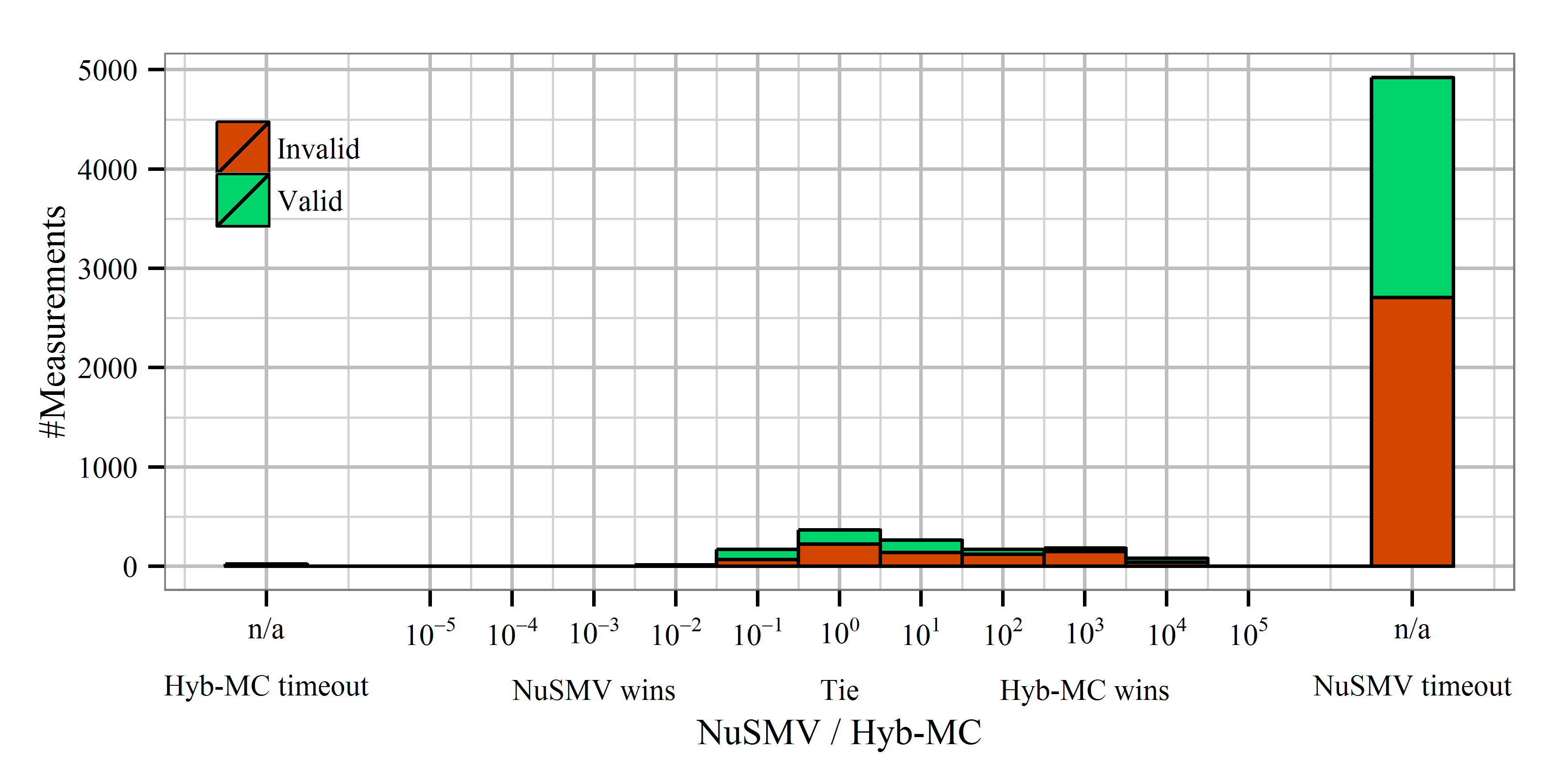
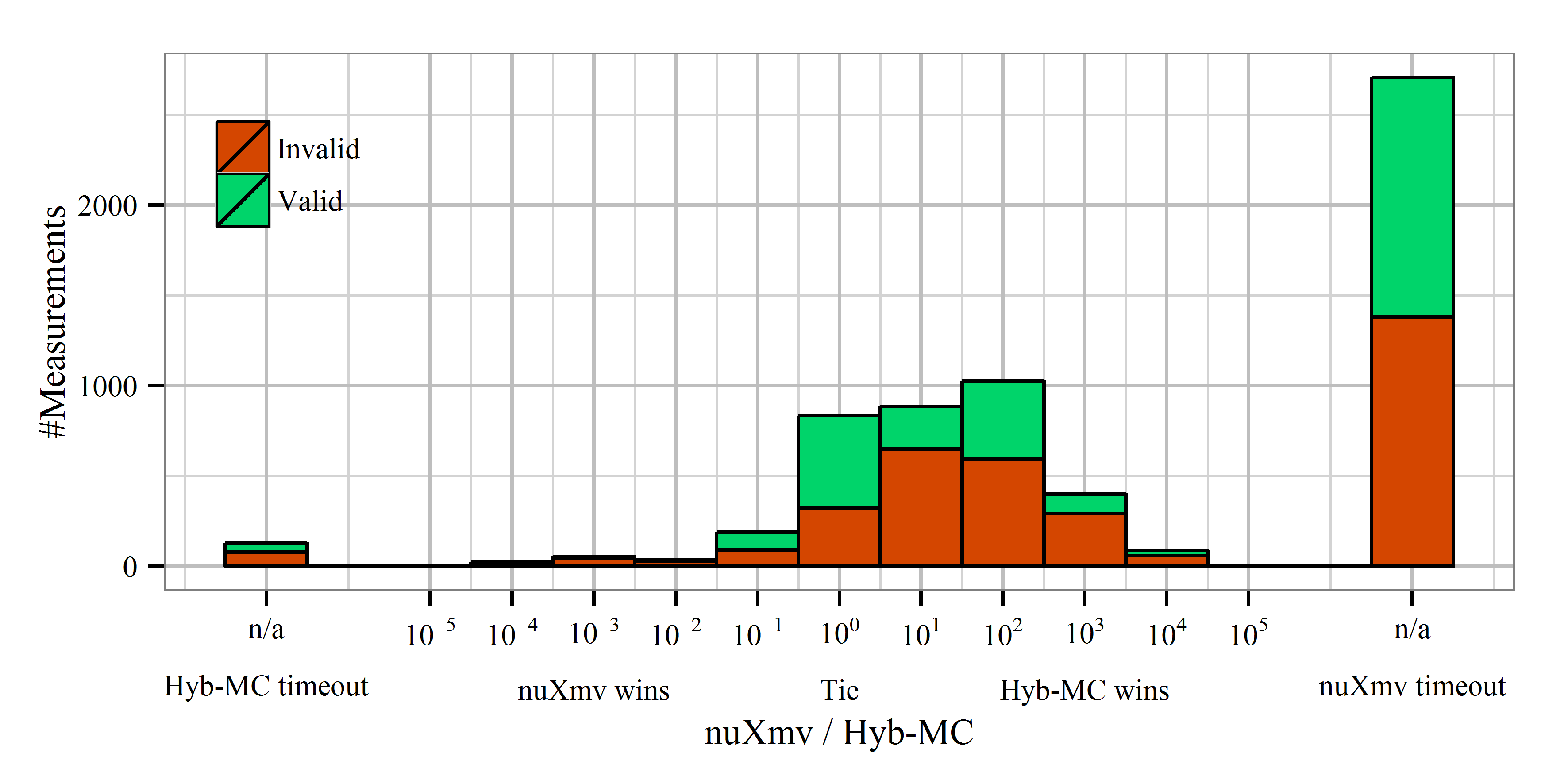
While the histograms do not show the exact time taken to verify the cases, the following plot depicts the number of cases that can be verified given a certain timeout. The reason of Hybrid MC and ITS intersecting the X axis later is that they both use SPOT to generate the Büchi automaton representation of the LTL properties, which gives a nearly constant overhead.